

DeepSeek R1 dropped like a plot twist in a story that everyone believed they already understood. A team of researchers produced a reason-based model that boasts industry-leading performance, and did so at a fraction of the cost everyone assumed. That one-two punch is reshaping how researchers, startups, and crypto projects approach model access, experimentation, and product strategy.
At the centre of the fuss is the R1 family: open-code, optimisation-for-reasoning models trained using a new, reinforcement-first approach. Authors claim R1 works on reasoning like some top-of-the-range proprietary models, without locking in weights or paying a comparatively extortionate training price. That alone is enough to get venture desks and engineering teams to sit up and take notice. (Nature)

DeepSeek R1: A New Era of Open Research Shaping Developers, Investors, and the Crypto Market (Image Source: CTech)
Why you should care today
- It lowers the bar for serious experimentation with leading-edge models of reasoning.
- Open weights enable more groups to experiment, audit, and build, not just spectate.
- 76The economics debunk assumptions about how much money and computing it takes to advance research.
This isn’t speakeasy theory. The story already has peer-reviewed backing and open repositories. That makes it news as well as a functional toolkit. (Nature)
What is DeepSeek R1, in simple words
DeepSeek R1 is a series of language models designed specifically to improve reasoning, multi-step mathematics, computer code logic, and sequenced problem-solving, for instance. The shift is methodological: instead of training the model mostly on human-authored reason examples, the researchers use a reinforcement-style approach that reinforces accurate results and lets the model figure out step-by-step methods on its own. The result, the paper argues, is emergent reason behavior without clunky human-annotated reason traces. (Nature)
The project also simplified the release of abridged versions along parameter sizes (small to extra-large), weights, and code to public platforms so that experiments can be replicated by researchers and scaled up to tasks. That openness is important: groups can fine-tune, do local evaluations, and compose pieces into products without vendor lock-in. (Hugging Face)
DeepSeek-R1 was published in Nature yesterday as the cover article for their BRILLIANT latest research.
They show that pure Reinforcement Learning with answer-only rewards can grow real reasoning skills, no human step-by-step traces required.
So completely skip human… pic.twitter.com/BC4g8YZH3v
— Rohan Paul (@rohanpaul_ai) September 18, 2025
The headline number: cost of training and why it matters
Some of the biggest surprises did not emerge from accuracy graphs but from accountants’ break rooms. DeepSeek found an estimate of training cost that’s lower than most expect: around US$294,000 to train the R1 model, a cost that, if reproducible and true, contradicts reports that newer models need to be constructed at millions or billions of dollars. This is in a peer-reviewed Nature paper, and some respectable outlets have picked up the news. (Reuters)
What the figure shows:
- Counting cost-effectiveness. Careful design choices and training routines can shave millions off costs.
- Open-source benefit. When techniques and weights are open, the community adds value beyond a single company’s product.
- New competitive dynamics. Startups and research labs with limited budgets can now design large-scale research programs, which were once limited by budget.
Brief background note on circumstances: some of the savings result from the research group’s specific makeup (chip mix, optimisations, dataset curation, and the reinforcement method). The details matter; you cannot achieve the headline number without the recipe. But the more important concern is structural: model builders now have a much clearer second avenue. (arXiv)
How the R1 method operates (brief overview)
- Cold-start and staged training. R1 employs staged training where the model is provided well-chosen “cold-start” data to seed behaviors before taking reinforcement steps.
- Pure reinforcement learning for reasoning. In place of human-annotated multi-step solutions at scale, the model is provided outcome-based rewards and a successful problem completion-biased training loop. The model is trained to affirm, reflect, and build internal strategies. (arXiv)
- Distillation and scaling. Researchers distill larger models into different sizes, so smaller groups can use less resource-intensive versions without sacrificing reasoning capacity. (Hugging Face)
The outcome: R1 is not just another model capable of producing reasonable text. It aims for measurable reasoning capacity on standard tests, math, code, logic problems, and multi-step reasoning exercises, and achieves this through a training schedule that avoids vast pools of human-annotated step-by-step traces.
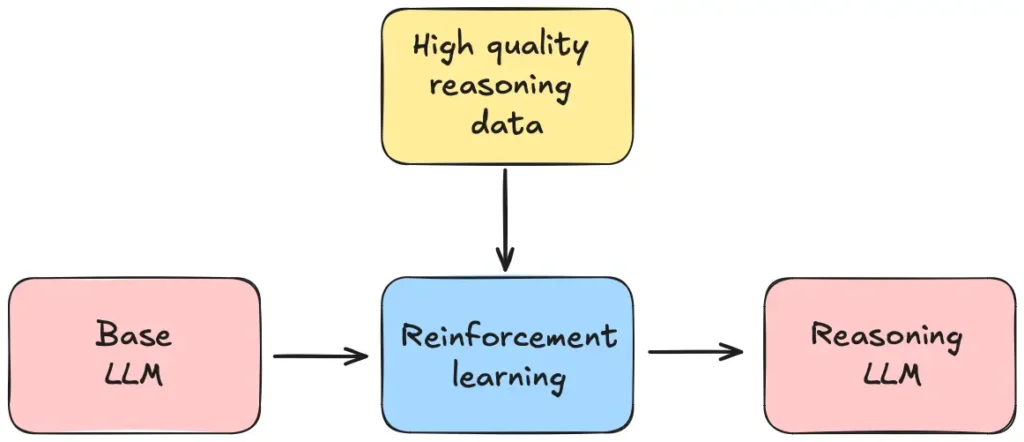
DeepSeek R1: From Cold-Start Training to Reinforcement and Distillation, A Scaled Approach Driving True Reasoning Power (Image Source: aman.ai)
Open-source release, why openness scales the impact
DeepSeek released model weights and code on public hosts, enabling mass reproducibility, third-party testing, and integration. Such openness transforms an academic result into an experimental force.
Consider the impact:
- Universities establish labs to replicate results and release counter-experiments.
- Startups incorporate R1 size bottlenecked features into specialist products (finance calculators, crypto contract analysers, on-device agents) without negotiating restrictive licenses.
- Security researchers examine model behavior and reveal failure modes in advance.
Open weights also invite close inspection. Biases and security risks in each high-impact system under scrutiny are revealed sooner, so the community can patch, adapt, and harden systems for production. That is research-first thinking. (Hugging Face)
The ripple through markets and crypto
Why would a reasoning model be of interest to crypto people? There are several direct lines of connection:
- Smart contract analysis and verification. Code-conscious models can be utilized to detect vulnerabilities, deconstruct contract behavior, and suggest patches. DeFi development teams can leverage smaller, offline models to run static analysis without exposing proprietary code to external APIs.
- On-chain analytics and signal synthesis. Multi-step logic-understanding models can generalize protocol updates, recognize advanced attack patterns, and help generate automated monitoring rules.
- Lower cost, more decentralised tooling. Low-cost, open models enable small Web3 teams and contract auditors to implement local tools that previously required cloud-scale budgets.
The union of reason, open weights, and low cost turbocharges decentralised tooling. That’s crypto security, governance tooling, and contract research goodness. (CoinDesk)
DeepSeek R1’s Reasoning Models: Powering Smarter Crypto Security, On-Chain Analytics, and Decentralised Tooling (Image Source: MDPI)
Industry pushback and geopolitical undertones
Not everybody is welcoming the sudden democratisation of mighty reason models. Two concerns leap to mind at once:
- Abuse and dual-use. The quality of the reasoning is a likelihood for the model to automate tasks of positive and negative value, from useful to harmful. Open weights suggest that both white-hat researchers and adversaries get access. This raises the demand for governance, responsible disclosure, and tooling.
- National adaptation and response. National champions and large tech react in different ways. Some are bespoke-developing R1 for national needs. One of China’s largest hardware and cloud providers, for example, has come out with an optimized-for-censorship-and-“value-alignment” version, illustrating the way open models get forked and re-tuned within a matter of weeks. That variant is more concerned with filtering and compliance with national rules than with open exploration. (Reuters)
These responses are a reminder that open tech happens in geopolitical settings. The same openness that accelerates innovation can accelerate fragmentation and regulatory battle.
Reproducibility, verification, and the Nature stamp
One reason that this story leaks into blogs outside of tech is the scholarly trail: R1 methodology and results are published in peer-reviewed journals. That sharply raises research validity and invites formal replication studies.
Peer review has two benefits:
- It requires more open method descriptions and testing procedures.
- It elicits expert criticism that’s harder to reject for policymakers and investors.
Summary: The Nature press coverage gives the discovery academic credibility and stimulates other labs to try to reproduce the claims, just what is needed if the goal is sustainable, community-tested progress. (Nature)
Developer experience and early adopters
Developers already confirm that distilled R1 models are worth it for resource-challenged environments. As the R1 family comes in numerous sizes, teams can build locally and then scale up. Real-world benefits are:
- Smoother iteration on logic-intensive tasks.
- Domain-specific reasoning with lower-cost fine-tunes.
- Deploy flexibility, local servers to cloud endpoints.
Community packages and documentation on the public repo enable simpler onboarding. That hands-on factor converts headline results into developer traction. (GitHub)
First batch of FAQs (quick answers)
Q: Is DeepSeek R1 open-source or proprietary?
A: The R1 family provides open weights and repositories with distilled variants for different sizes.
Q: How did DeepSeek succeed in training R1 so economically?
A: Scientists had employed an effective combination of reinforcement-first training, strict dataset strategies, and computational optimisations. The figure published is ~US$294,000 for core training but relies upon hardware and training protocols chosen for reproducing that performance.
Q: Is R1 safe to deploy in production?
A: Safety depends on auditing, tuning, and governance. Open weights enable auditors to test behavior, but open access also introduces the risk of misuse. Utilize R1 as with any powerful tool: gauge, watch, and sandbox.
Benchmarks, where R1 shines and where it still falls short
Vendor and standalone benchmarks place R1 firmly in the “reasoning-specialist” class. Different tests set R1 at parity with top-performing reasoning systems on mathematics and structured reasoning batteries, though a few proprietary models still have the advantage on live coding as well as certain multilingual tasks. These numbers come from the first release notes, a peer-reviewed paper, as well as some community analyses. (arXiv)
What you should take away from those numbers
- Math and multi-step reasoning: R1 excels most at MATH/AIME-style problems and chains of multi-step reasoning. That is what is optimized by reinforcement-first training. (arXiv)
- Code generation and live coding metrics: Commercial models still dominate R1 on live coding and difficult code synthesis, where supervised fine-tuning on massive labeled datasets is useful. Community comparisons have R1 competitive but not quite the best in coding.
- Latency, context window, and distilled sizes: Distilled R1 variants offer groups realistic deployment points, from infinitesimal on-prem models to enormous cloud instances. That interval makes it feasible where heavyweight cloud inference is not. Repository listings and distill releases offer diverse parameter sizes and context lengths. (GitHub)
That is to say: R1 is no general-purpose miracle, but a specialized, high-value tool for tasks requiring constant, verifiable stepwise reasoning.
Real-world applications that are applicable today (crypto, fintech, research labs)
These are real, near-future applications where R1 strengths become concrete value.
- Auditing and interpreting smart contracts
R1’s reasoning power lets it know contract logic, reveal likely invariants, and specify state transitions in several steps in natural language. R1 models can be run off-line and pulled out for teams to execute and test contracts before deployment, with less exposure to external APIs. (This also reduces leak risk for proprietary contracts.) (Hugging Face)
- On-chain automated incident triage
When exploits do occur, speed is crucial. R1 can reduce multi-source signals (event traces, transaction graphs, protocol documents) to a concise causal narrative and actionable engineers’ and ops’ checklists. Because the model encourages auditable steps, its output will be inclined to be auditable.
- Financial modelling and scenario reasoning
For product and quant research teams, R1 helps create logic in scenario models (conditional flows, what-if chains). Teams still validate numeric results with standard tools, but R1 accelerates ideation and hypothesis creation.
- Research labs and reproducibility pipelines
Researchers use distilled versions of R1 models for low-budget tests of robustness and reasoning, and open weights allow independent replication and criticism, something that the peer-review process actively encourages.
Caveat: these advantages are open to disciplined evaluation and sandboxing. Model behavior is momentary framing- and fine-tune data-dependent; do not accept output as authoritative without automated verification pipelines.
Safety, governance, and hostile-use considerations
Open-weight, high-capability models of reasoning change the threat matrix. DeepSeek generates jailbreak and abuse threats by itself; the security community is stress-testing releases already. Be on the lookout for forks, patched releases, and nation-level customizations, some of which will include safety filters as a top priority, others of which will not. (South China Morning Post)
Primary threats to counter:
- Direct attacks and jailbreaks: Reasoning models can be manipulated into leaking inner chains or taking on roles, bypassing filters. Consider any open model exposed until hardened. (South China Morning Post)
- Manipulated or biased outputs: Reward signal-trained models also carry dataset blind spots as well as geopolitical bias. Independent audits and red-team tests matter. (Tom’s Hardware)
- Dual-use of quality code generation: Appropriate for auditing, but useful to attackers, as well. Use rate limiting, provenance tracking, and code-quality checks.

DeepSeek R1: Balancing Safety, Governance, and Dual-Use Risks in Open-Weight Reasoning Models (Image Source: South China Morning Post)
How to review R1 securely and effectively: a checklist for teams
Make use of the following checklist as an achievable starting point before deploying R1 to production.
- Reproducibility test: Plot the published distilled model, run the official benchmark scripts from the repo, and make sure you get the same scores. (GitHub and Hugging Face hosts are files.) (GitHub)
- Unit verification harness: Build a test suite that tests model outputs step-by-step, e.g., does the model produce intermediate working equal to a verifiable chain? Use deterministic prompts wherever possible.
- Red-team questions: Conduct jailbreak and instruction-manipulation testing. Keep a set of questions that induce unsafe behavior and funnel them through to your monitoring.
- Bias and region-sensitivity audit: Test the model on region-specific and sensitive questions to reveal discrepancies. Make use of third-party auditors if the use case encroaches on governance or high-stakes finance.
- On-chain and code safety verification: If using the model for smart contract output, pass code through existing static analysis tools and human review before deploying anything. (Hugging Face)
- Operational sandboxing: Start offline deployments, stringent data-exfiltration controls, token limits, and logging. Progress to online inference only with multi-layered monitoring. (DeepSeek API Docs)
Following these steps allows teams to translate model capability into reproducible product behavior.
Deployment and cost reality
R1 release is cost-of-training-prioritized, but deployment is still size-variable, inference hardware- and usage-pattern-dependent. Distilled models offer practical trade-offs: smaller size for lower latency and lower-cost hosting; larger size for highest performance. DeepSeek publications and third-party hosting reveal a few pricing and hosting options that make it simple to adopt experiments.
Watch out: headline training cost makes headlines, but replication cost and production inference cost remain organisation-specific. Pundits and some media question the naive interpretation of the training number, take it as a useful data point, not the whole picture. (Reuters)
Peer reviewed version of Deepseek R1 paper in Nature.
Hard to believe it’s only been 9 months since R1 – seems like a lifetime ago!
“The paper updates a preprint released in January, which describes how DeepSeek augmented a standard large language model (LLM) to tackle… pic.twitter.com/td91YJ6Rwx
— steve hsu (@hsu_steve) September 18, 2025
Full FAQ, practical answers (brief, to the point)
Is R1 open-source?
Yes, weights and code are available from public repositories and model hubs, including GitHub and Hugging Face.
Is R1 really trained with reinforcement training without supervised traces?
The paper describes a reinforcement-first method and models that were mainly trained with reward-based optimisation. Nature/arXiv content summarises the approach. (Nature)
Can I run R1 on-prem?
Yes, distilled models are offered in particular to support on-prem and lower-cost deployments. Hardware requirements rise with parameter size.
Is $294k training cost the whole story?
No. DeepSeek quotes that number for a core training run; outside experts warn and quote other development costs and pretraining expenditures.
How does R1 compare to leading proprietary models?
It is competitive with or on a par with leading models on math and systematic reasoning; a few commercial systems continue to be stronger at some code and multimodal tasks.
Are there safety-hardened variants?
Other organizations fork R1 for the addition of censorship or safety filters; that work continues and is reflected in news and vendor accounts.
Can I use R1 for automatic contract repair?
Use it as a patch-proposing tool; always look at suggested changes with human eyeballs and meticulous static analysis.
Will regulators step in?
Yes, open, capable models are prepared to stand up to scrutiny. Look out for geographically targeted limitations on model use and distribution, and compliance audits.
Does R1 reduce vendor lock-in?
Open tooling and distill models reduce lock-in risk and enable teams to run models locally rather than be locked into a single cloud provider.
How fast can teams prototype with R1?
Distilled repo, open tooling, and community accelerate prototyping. Prototyping is quicker for most teams thanks to distilled sizes and example scripts.
How to fine-tune best for a special domain?
Begin from a distilled variant, gather a high-quality domain dataset, and fine-tune with conservative reward shaping and a safety validation set. (arXiv)
Are R1 top clouds ready?
Yes, several model hubs and cloud providers include R1 or variants to ease integration. (The Verge)
Is it reversible to train data leak with R1?
Any large model can memorize data; employ membership inference tests and limit sensitive-data exposure on fine-tuning.
Who should not use R1?
Only raw releases should not be used in production for high-risk decisions by mature safety and verification pipelines.
How can I assist with attempts at replication?
Join open reproduction repos and joint benchmarking efforts, GitHub and Hugging Face communities organize reproducibility events.
Strategic takeaways for investors, builders, and policy-makers
Investors: R1 illustrates innovation may be achieved by smarter design of methods, rather than in terms of higher budgets. Portfolio plays: products that consolidate distills for vertical markets (security, audit, on-device inference) will see early revenue. But geopolitics and price pressure are a threat, discounting regulatory and supply-chain uncertainty when valuing.
Builders: Leverage R1 as a reasoner for product features that require heavy reasoning (contract analysis, decision support, research assistants). Prioritize reproducibility, build safety test harnesses on day one, and design for hybrid deployments (on-prem + cloud).
Policy-makers: Open releases and peer-reviewed publications increase transparency and scientific rigor. Open access, however, also raises vectors of misuse. Policies need to promote transparency and facilitate independent audits and ensure practicable safeguards for sensitive domains.
Last thought (brief)
DeepSeek R1 flips the conversation on its head from “how much money” to “how smartly” we train and use reasoning systems. That’s crucial to all creators creating in crypto, finance, or research: ability is now more a matter of method, verification, and governance than scale. The hard work, secure integration, sound validatio, and smart product design remain ours to do.